Saving and Loading Checkpoints#
Ray Train provides a way to snapshot training progress with Checkpoints.
This is useful for:
Storing the best-performing model weights: Save your model to persistent storage, and use it for downstream serving/inference.
Fault tolerance: Handle node failures in a long-running training job on a cluster of pre-emptible machines/pods.
Distributed checkpointing: When doing model-parallel training, Ray Train checkpointing provides an easy way to upload model shards from each worker in parallel, without needing to gather the full model to a single node.
Integration with Ray Tune: Checkpoint saving and loading is required by certain Ray Tune schedulers.
Saving checkpoints during training#
The Checkpoint is a lightweight interface provided
by Ray Train that represents a directory that exists on local or remote storage.
For example, a checkpoint could point to a directory in cloud storage:
s3://my-bucket/my-checkpoint-dir.
A locally available checkpoint points to a location on the local filesystem:
/tmp/my-checkpoint-dir.
Here’s how you save a checkpoint in the training loop:
Write your model checkpoint to a local directory.
Since a
Checkpointjust points to a directory, the contents are completely up to you.This means that you can use any serialization format you want.
This makes it easy to use familiar checkpoint utilities provided by training frameworks, such as
torch.save,pl.Trainer.save_checkpoint, Accelerate’saccelerator.save_model, Transformers’save_pretrained,tf.keras.Model.save, etc.
Create a
Checkpointfrom the directory usingCheckpoint.from_directory.Report the checkpoint to Ray Train using
ray.train.report(metrics, checkpoint=...).The metrics reported alongside the checkpoint are used to keep track of the best-performing checkpoints.
This will upload the checkpoint to persistent storage if configured. See Configuring Persistent Storage.
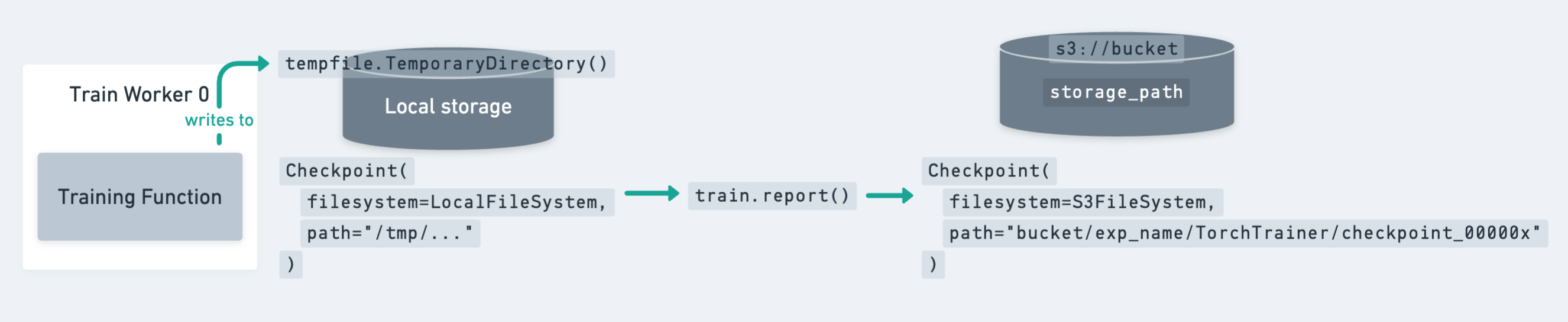
The lifecycle of a Checkpoint, from being saved locally
to disk to being uploaded to persistent storage via train.report.#
As shown in the figure above, the best practice for saving checkpoints is to
first dump the checkpoint to a local temporary directory. Then, the call to train.report
uploads the checkpoint to its final persistent storage location.
Then, the local temporary directory can be safely cleaned up to free up disk space
(e.g., from exiting the tempfile.TemporaryDirectory context).
Tip
In standard DDP training, where each worker has a copy of the full-model, you should only save and report a checkpoint from a single worker to prevent redundant uploads.
This typically looks like:
import tempfile
from ray import train
def train_fn(config):
...
metrics = {...}
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
# Only the global rank 0 worker saves and reports the checkpoint
if train.get_context().get_world_rank() == 0:
... # Save checkpoint to temp_checkpoint_dir
checkpoint = Checkpoint.from_directory(tmpdir)
train.report(metrics, checkpoint=checkpoint)
If using parallel training strategies such as DeepSpeed Zero-3 and FSDP, where each worker only has a shard of the full-model, you should save and report a checkpoint from each worker. See Saving checkpoints from multiple workers (distributed checkpointing) for an example.
Here are a few examples of saving checkpoints with different training frameworks:
import os
import tempfile
import numpy as np
import torch
import torch.nn as nn
from torch.optim import Adam
import ray.train.torch
from ray import train
from ray.train import Checkpoint, ScalingConfig
from ray.train.torch import TorchTrainer
def train_func(config):
n = 100
# create a toy dataset
# data : X - dim = (n, 4)
# target : Y - dim = (n, 1)
X = torch.Tensor(np.random.normal(0, 1, size=(n, 4)))
Y = torch.Tensor(np.random.uniform(0, 1, size=(n, 1)))
# toy neural network : 1-layer
# Wrap the model in DDP
model = ray.train.torch.prepare_model(nn.Linear(4, 1))
criterion = nn.MSELoss()
optimizer = Adam(model.parameters(), lr=3e-4)
for epoch in range(config["num_epochs"]):
y = model.forward(X)
loss = criterion(y, Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
metrics = {"loss": loss.item()}
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
should_checkpoint = epoch % config.get("checkpoint_freq", 1) == 0
# In standard DDP training, where the model is the same across all ranks,
# only the global rank 0 worker needs to save and report the checkpoint
if train.get_context().get_world_rank() == 0 and should_checkpoint:
torch.save(
model.module.state_dict(), # NOTE: Unwrap the model.
os.path.join(temp_checkpoint_dir, "model.pt"),
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
train.report(metrics, checkpoint=checkpoint)
trainer = TorchTrainer(
train_func,
train_loop_config={"num_epochs": 5},
scaling_config=ScalingConfig(num_workers=2),
)
result = trainer.fit()
Tip
You most likely want to unwrap the DDP model before saving it to a checkpoint.
model.module.state_dict() is the state dict without each key having a "module." prefix.
Ray Train leverages PyTorch Lightning’s Callback interface to report metrics
and checkpoints. We provide a simple callback implementation that reports
on_train_epoch_end.
Specifically, on each train epoch end, it
collects all the logged metrics from
trainer.callback_metricssaves a checkpoint via
trainer.save_checkpointreports to Ray Train via
ray.train.report(metrics, checkpoint)
import pytorch_lightning as pl
from ray import train
from ray.train.lightning import RayTrainReportCallback
from ray.train.torch import TorchTrainer
class MyLightningModule(pl.LightningModule):
# ...
def on_validation_epoch_end(self):
...
mean_acc = calculate_accuracy()
self.log("mean_accuracy", mean_acc, sync_dist=True)
def train_func():
...
model = MyLightningModule(...)
datamodule = MyLightningDataModule(...)
trainer = pl.Trainer(
# ...
callbacks=[RayTrainReportCallback()]
)
trainer.fit(model, datamodule=datamodule)
ray_trainer = TorchTrainer(
train_func,
scaling_config=train.ScalingConfig(num_workers=2),
run_config=train.RunConfig(
checkpoint_config=train.CheckpointConfig(
num_to_keep=2,
checkpoint_score_attribute="mean_accuracy",
checkpoint_score_order="max",
),
),
)
You can always get the saved checkpoint path from result.checkpoint and
result.best_checkpoints.
For more advanced usage (e.g. reporting at different frequency, reporting customized checkpoint files), you can implement your own customized callback. Here is a simple example that reports a checkpoint every 3 epochs:
import os
from tempfile import TemporaryDirectory
from pytorch_lightning.callbacks import Callback
import ray
import ray.train
from ray.train import Checkpoint
class CustomRayTrainReportCallback(Callback):
def on_train_epoch_end(self, trainer, pl_module):
should_checkpoint = trainer.current_epoch % 3 == 0
with TemporaryDirectory() as tmpdir:
# Fetch metrics
metrics = trainer.callback_metrics
metrics = {k: v.item() for k, v in metrics.items()}
# Add customized metrics
metrics["epoch"] = trainer.current_epoch
metrics["custom_metric"] = 123
checkpoint = None
global_rank = ray.train.get_context().get_world_rank() == 0
if global_rank == 0 and should_checkpoint:
# Save model checkpoint file to tmpdir
ckpt_path = os.path.join(tmpdir, "ckpt.pt")
trainer.save_checkpoint(ckpt_path, weights_only=False)
checkpoint = Checkpoint.from_directory(tmpdir)
# Report to train session
ray.train.report(metrics=metrics, checkpoint=checkpoint)
Ray Train leverages HuggingFace Transformers Trainer’s Callback interface
to report metrics and checkpoints.
Option 1: Use Ray Train’s default report callback
We provide a simple callback implementation RayTrainReportCallback that
reports on checkpoint save. You can change the checkpointing frequency by save_strategy and save_steps.
It collects the latest logged metrics and report them together with the latest saved checkpoint.
from transformers import TrainingArguments
from ray import train
from ray.train.huggingface.transformers import RayTrainReportCallback, prepare_trainer
from ray.train.torch import TorchTrainer
def train_func(config):
...
# Configure logging, saving, evaluation strategies as usual.
args = TrainingArguments(
...,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_strategy="step",
)
trainer = transformers.Trainer(args, ...)
# Add a report callback to transformers Trainer
# =============================================
trainer.add_callback(RayTrainReportCallback())
trainer = prepare_trainer(trainer)
trainer.train()
ray_trainer = TorchTrainer(
train_func,
run_config=train.RunConfig(
checkpoint_config=train.CheckpointConfig(
num_to_keep=3,
checkpoint_score_attribute="eval_loss", # The monitoring metric
checkpoint_score_order="min",
)
),
)
Note that RayTrainReportCallback
binds the latest metrics and checkpoints together,
so users can properly configure logging_strategy, save_strategy and evaluation_strategy
to ensure the monitoring metric is logged at the same step as checkpoint saving.
For example, the evaluation metrics (eval_loss in this case) are logged during
evaluation. If users want to keep the best 3 checkpoints according to eval_loss, they
should align the saving and evaluation frequency. Below are two examples of valid configurations:
args = TrainingArguments(
...,
evaluation_strategy="epoch",
save_strategy="epoch",
)
args = TrainingArguments(
...,
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=50,
save_steps=100,
)
# And more ...
Option 2: Implement your customized report callback
If you feel that Ray Train’s default RayTrainReportCallback
is not sufficient for your use case, you can also implement a callback yourself!
Below is a example implementation that collects latest metrics
and reports on checkpoint save.
from ray import train
from transformers.trainer_callback import TrainerCallback
class MyTrainReportCallback(TrainerCallback):
def __init__(self):
super().__init__()
self.metrics = {}
def on_log(self, args, state, control, model=None, logs=None, **kwargs):
"""Log is called on evaluation step and logging step."""
self.metrics.update(logs)
def on_save(self, args, state, control, **kwargs):
"""Event called after a checkpoint save."""
checkpoint = None
if train.get_context().get_world_rank() == 0:
# Build a Ray Train Checkpoint from the latest checkpoint
checkpoint_path = transformers.trainer.get_last_checkpoint(args.output_dir)
checkpoint = Checkpoint.from_directory(checkpoint_path)
# Report to Ray Train with up-to-date metrics
ray.train.report(metrics=self.metrics, checkpoint=checkpoint)
# Clear the metrics buffer
self.metrics = {}
You can customize when (on_save, on_epoch_end, on_evaluate) and
what (customized metrics and checkpoint files) to report by implementing your own
Transformers Trainer callback.
Saving checkpoints from multiple workers (distributed checkpointing)#
In model parallel training strategies where each worker only has a shard of the full-model, you can save and report checkpoint shards in parallel from each worker.
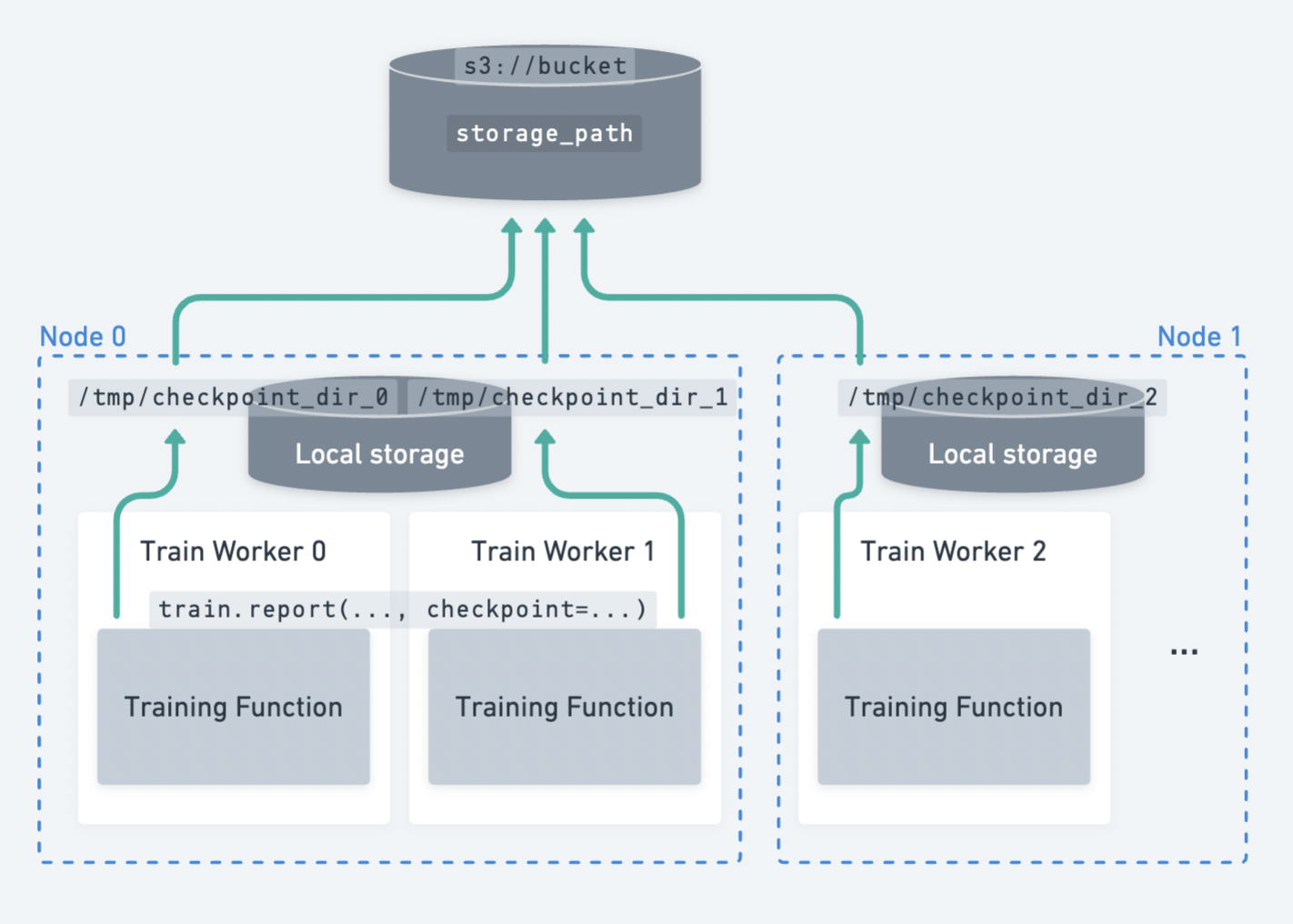
Distributed checkpointing in Ray Train. Each worker uploads its own checkpoint shard to persistent storage independently.#
Distributed checkpointing is the best practice for saving checkpoints when doing model-parallel training (e.g., DeepSpeed, FSDP, Megatron-LM).
There are two major benefits:
It is faster, resulting in less idle time. Faster checkpointing incentivizes more frequent checkpointing!
Each worker can upload its checkpoint shard in parallel, maximizing the network bandwidth of the cluster. Instead of a single node uploading the full model of size
M, the cluster distributes the load acrossNnodes, each uploading a shard of sizeM / N.Distributed checkpointing avoids needing to gather the full model onto a single worker’s CPU memory.
This gather operation puts a large CPU memory requirement on the worker that performs checkpointing and is a common source of OOM errors.
Here is an example of distributed checkpointing with PyTorch:
from ray import train
from ray.train import Checkpoint
from ray.train.torch import TorchTrainer
def train_func(config):
...
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
rank = train.get_context().get_world_rank()
torch.save(
...,
os.path.join(temp_checkpoint_dir, f"model-rank={rank}.pt"),
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
train.report(metrics, checkpoint=checkpoint)
trainer = TorchTrainer(
train_func,
scaling_config=train.ScalingConfig(num_workers=2),
run_config=train.RunConfig(storage_path="s3://bucket/"),
)
# The checkpoint in cloud storage will contain: model-rank=0.pt, model-rank=1.pt
Note
Checkpoint files with the same name will collide between workers. You can get around this by adding a rank-specific suffix to checkpoint files.
Note that having filename collisions does not error, but it will result in the last uploaded version being the one that is persisted. This is fine if the file contents are the same across all workers.
Model shard saving utilities provided by frameworks such as DeepSpeed will create rank-specific filenames already, so you usually do not need to worry about this.
Configure checkpointing#
Ray Train provides some configuration options for checkpointing via CheckpointConfig.
The primary configuration is keeping only the top K checkpoints with respect to a metric.
Lower-performing checkpoints are deleted to save storage space. By default, all checkpoints are kept.
from ray.train import RunConfig, CheckpointConfig
# Example 1: Only keep the 2 *most recent* checkpoints and delete the others.
run_config = RunConfig(checkpoint_config=CheckpointConfig(num_to_keep=2))
# Example 2: Only keep the 2 *best* checkpoints and delete the others.
run_config = RunConfig(
checkpoint_config=CheckpointConfig(
num_to_keep=2,
# *Best* checkpoints are determined by these params:
checkpoint_score_attribute="mean_accuracy",
checkpoint_score_order="max",
),
# This will store checkpoints on S3.
storage_path="s3://remote-bucket/location",
)
Note
If you want to save the top num_to_keep checkpoints with respect to a metric via
CheckpointConfig,
please ensure that the metric is always reported together with the checkpoints.
Using checkpoints after training#
The latest saved checkpoint can be accessed with Result.checkpoint.
The full list of persisted checkpoints can be accessed with Result.best_checkpoints.
If CheckpointConfig(num_to_keep) is set, this list will contain the best num_to_keep checkpoints.
See Inspecting Training Results for a full guide on inspecting training results.
Checkpoint.as_directory
and Checkpoint.to_directory
are the two main APIs to interact with Train checkpoints:
from pathlib import Path
from ray.train import Checkpoint
# For demonstration, create a locally available directory with a `model.pt` file.
example_checkpoint_dir = Path("/tmp/test-checkpoint")
example_checkpoint_dir.mkdir()
example_checkpoint_dir.joinpath("model.pt").touch()
# Create the checkpoint, which is a reference to the directory.
checkpoint = Checkpoint.from_directory(example_checkpoint_dir)
# Inspect the checkpoint's contents with either `as_directory` or `to_directory`:
with checkpoint.as_directory() as checkpoint_dir:
assert Path(checkpoint_dir).joinpath("model.pt").exists()
checkpoint_dir = checkpoint.to_directory()
assert Path(checkpoint_dir).joinpath("model.pt").exists()
For Lightning and Transformers, if you are using the default RayTrainReportCallback for checkpoint saving in your training function,
you can retrieve the original checkpoint files as below:
# After training finished
checkpoint = result.checkpoint
with checkpoint.as_directory() as checkpoint_dir:
lightning_checkpoint_path = f"{checkpoint_dir}/checkpoint.ckpt"
# After training finished
checkpoint = result.checkpoint
with checkpoint.as_directory() as checkpoint_dir:
hf_checkpoint_path = f"{checkpoint_dir}/checkpoint/"
Restore training state from a checkpoint#
In order to enable fault tolerance, you should modify your training loop to restore
training state from a Checkpoint.
The Checkpoint to restore from can be accessed in the
training function with ray.train.get_checkpoint.
The checkpoint returned by ray.train.get_checkpoint is populated in two ways:
It can be auto-populated as the latest reported checkpoint, e.g. during automatic failure recovery or on manual restoration.
It can be manually populated by passing a checkpoint to the
resume_from_checkpointargument of a RayTrainer. This is useful for initializing a new training run with a previous run’s checkpoint.
import os
import tempfile
import numpy as np
import torch
import torch.nn as nn
from torch.optim import Adam
import ray.train.torch
from ray import train
from ray.train import Checkpoint, ScalingConfig
from ray.train.torch import TorchTrainer
def train_func(config):
n = 100
# create a toy dataset
# data : X - dim = (n, 4)
# target : Y - dim = (n, 1)
X = torch.Tensor(np.random.normal(0, 1, size=(n, 4)))
Y = torch.Tensor(np.random.uniform(0, 1, size=(n, 1)))
# toy neural network : 1-layer
model = nn.Linear(4, 1)
optimizer = Adam(model.parameters(), lr=3e-4)
criterion = nn.MSELoss()
# Wrap the model in DDP and move it to GPU.
model = ray.train.torch.prepare_model(model)
# ====== Resume training state from the checkpoint. ======
start_epoch = 0
checkpoint = train.get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as checkpoint_dir:
model_state_dict = torch.load(
os.path.join(checkpoint_dir, "model.pt"),
# map_location=..., # Load onto a different device if needed.
)
model.module.load_state_dict(model_state_dict)
optimizer.load_state_dict(
torch.load(os.path.join(checkpoint_dir, "optimizer.pt"))
)
start_epoch = (
torch.load(os.path.join(checkpoint_dir, "extra_state.pt"))["epoch"] + 1
)
# ========================================================
for epoch in range(start_epoch, config["num_epochs"]):
y = model.forward(X)
loss = criterion(y, Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
metrics = {"loss": loss.item()}
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
should_checkpoint = epoch % config.get("checkpoint_freq", 1) == 0
# In standard DDP training, where the model is the same across all ranks,
# only the global rank 0 worker needs to save and report the checkpoint
if train.get_context().get_world_rank() == 0 and should_checkpoint:
# === Make sure to save all state needed for resuming training ===
torch.save(
model.module.state_dict(), # NOTE: Unwrap the model.
os.path.join(temp_checkpoint_dir, "model.pt"),
)
torch.save(
optimizer.state_dict(),
os.path.join(temp_checkpoint_dir, "optimizer.pt"),
)
torch.save(
{"epoch": epoch},
os.path.join(temp_checkpoint_dir, "extra_state.pt"),
)
# ================================================================
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
train.report(metrics, checkpoint=checkpoint)
if epoch == 1:
raise RuntimeError("Intentional error to showcase restoration!")
trainer = TorchTrainer(
train_func,
train_loop_config={"num_epochs": 5},
scaling_config=ScalingConfig(num_workers=2),
run_config=train.RunConfig(failure_config=train.FailureConfig(max_failures=1)),
)
result = trainer.fit()
# Seed a training run with a checkpoint using `resume_from_checkpoint`
trainer = TorchTrainer(
train_func,
train_loop_config={"num_epochs": 5},
scaling_config=ScalingConfig(num_workers=2),
resume_from_checkpoint=result.checkpoint,
)
import os
from ray import train
from ray.train import Checkpoint
from ray.train.torch import TorchTrainer
from ray.train.lightning import RayTrainReportCallback
def train_func():
model = MyLightningModule(...)
datamodule = MyLightningDataModule(...)
trainer = pl.Trainer(..., callbacks=[RayTrainReportCallback()])
checkpoint = train.get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as ckpt_dir:
ckpt_path = os.path.join(ckpt_dir, "checkpoint.ckpt")
trainer.fit(model, datamodule=datamodule, ckpt_path=ckpt_path)
else:
trainer.fit(model, datamodule=datamodule)
# Build a Ray Train Checkpoint
# Suppose we have a Lightning checkpoint at `s3://bucket/ckpt_dir/checkpoint.ckpt`
checkpoint = Checkpoint("s3://bucket/ckpt_dir")
# Resume training from checkpoint file
ray_trainer = TorchTrainer(
train_func,
scaling_config=train.ScalingConfig(num_workers=2),
resume_from_checkpoint=checkpoint,
)
Note
In these examples, Checkpoint.as_directory
is used to view the checkpoint contents as a local directory.
If the checkpoint points to a local directory, this method just returns the local directory path without making a copy.
If the checkpoint points to a remote directory, this method will download the checkpoint to a local temporary directory and return the path to the temporary directory.
If multiple processes on the same node call this method simultaneously, only a single process will perform the download, while the others wait for the download to finish. Once the download finishes, all processes receive the same local (temporary) directory to read from.
Once all processes have finished working with the checkpoint, the temporary directory is cleaned up.